How Quartr Helps Kepler Build Citation-Grade Earnings Research

This post was originally published on Quartr’s blog.
A research analyst’s job is unforgiving. Every number in a model has to survive a PM pointing at it and asking where it came from. Every line of management commentary has to survive the same person pulling up the transcript. Every slide reference has to survive someone opening the deck to that page. Credibility compounds over years and erodes in seconds.
That is the work Kepler is built to do.
Kepler is the verifiability layer for AI. Kepler for Finance, our first product, lets analysts at hedge funds, PE shops, and investment banks query SEC filings, earnings calls, and IR materials together, and trace every number, quote, and slide reference back to its exact source. The goal is research the analyst can defend in the room they work in.
This post is about how we make that possible across the earnings event, and where Quartr fits.
AI interprets. Code executes. They never cross lanes.
The defining design decision in Kepler is that the language model never touches the numbers.
When an analyst asks Kepler a question, the AI layer does what language models are good at. It parses what the analyst meant, decomposes the question into sub-problems, decides which sources and which calculations are needed, and writes the narrative answer at the end. It interprets, plans, and composes.
The numbers themselves come from a different layer. Every figure that appears in a Kepler answer is fetched by deterministic code from a pre-extracted, provenance-tracked store. Every derived metric is computed by deterministic code using a fixed formula. Every citation is a pointer to a specific filing, page, line item, transcript passage, or slide phrase, attached at the moment the underlying data was extracted, not generated after the fact.
A proprietary financial ontology mediates between the two layers, so the language model and the retrieval layer speak the same vocabulary of companies, filings, line items, and events.
That single property is what makes the platform auditable. Same question, same underlying data, same answer, every time. If a number is wrong, the cause is in the extraction pipeline or the formula, and both are inspectable.
Where Quartr fits
Three sources matter for a typical earnings event question, and Kepler pre-extracts all three.
The SEC filing tells you what happened. The earnings call transcript tells you why, and what management thinks happens next. The IR slide deck tells you what management wants the market to see.
We pull the transcript and the slide deck from Quartr. Their API gives us first-party IR content across 15,000+ companies and 65+ markets, structured and ready for retrieval. Our pipeline ingests each transcript, segments prepared remarks from Q&A, tags speakers, and timestamps passages. It extracts slide content at the phrase level with page and bounding-box coordinates, so a citation can land on the exact line of the right slide, not just on the deck as a whole.
Standing up that layer without a partner like Quartr would have meant either running our own transcription and IR-scraping operation at that scale, or relying on aggregators with quality and timeliness gaps we would compensate for downstream. Neither cleared our bar. Quartr did.
We extract once, normalize, store, and serve from our own infrastructure. The analyst is never waiting on a fresh fetch.
What this looks like in a real query
Consider a question we see often: “Walk me through the bridge between management’s tone on margin pressure this quarter, what they reported in the income statement, and what they put on the IR deck.”
Kepler returns a single cited synthesis pulling from the 10-Q, the Quartr transcript, and the Quartr IR deck for the same period. Every figure, quote, and slide reference is click-through: a number opens the 10-Q at the cited line item, a quote opens the Quartr transcript at the timestamp and speaker, a slide reference opens the IR deck on the cited page with the phrase highlighted.
What used to be tens of minutes of reconciling tabs, scrolling transcripts, and screenshotting slides becomes a few seconds of work the analyst can verify line by line before sending it on. The verification step is the point.
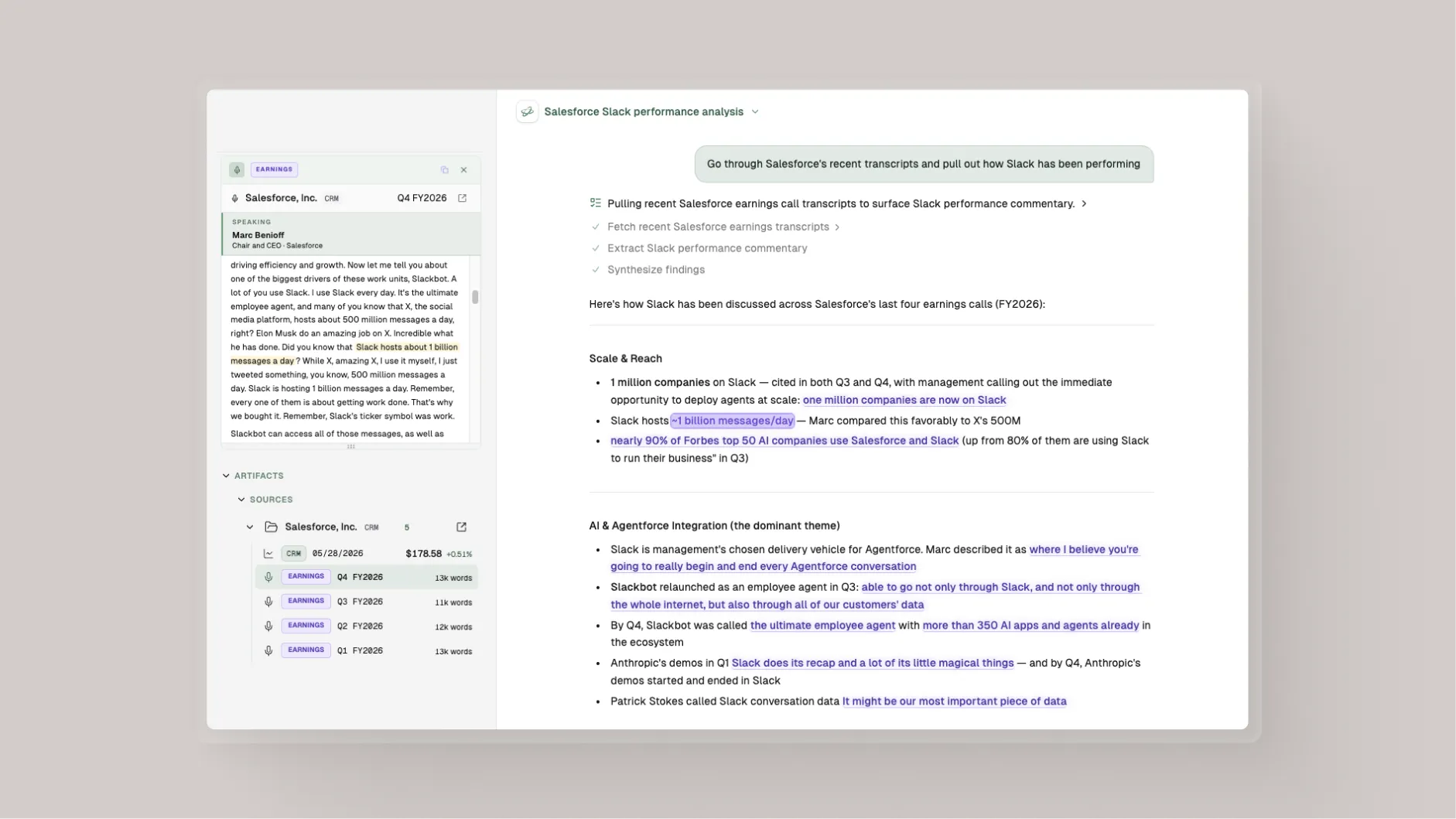
A Kepler answer in flight. Every cited claim links back to the exact transcript passage and speaker.
Why this is the standard
The standard hallucination story is incomplete. Wrong-and-obvious is not the dangerous failure mode in finance. Wrong-and-plausible is, and it is the architectural consequence of letting the language model produce the numbers.
Kepler removes that mode at the design level. Numbers are fetched, not generated. Computations run as fixed formulas in deterministic code. Citations are pointers attached to a figure at extraction time. The model can still get the interpretation wrong, and we have ways to catch that, but it cannot produce a confidently incorrect number, because it does not produce numbers.
That is the standard we hold ourselves to. Verifiably correct, not likely correct.
From Quartr
We asked Oscar Küntzel, Quartr’s co-founder and CEO, for his take on the partnership.
“Financial AI has had a foundational problem from day one. Earnings calls, transcripts, and filings, the primary inputs in company research, were built for humans to read one at a time, not for AI to query across thousands of companies. Kepler is one of the sharpest teams we’ve seen building on top of Quartr API, turning clean, first-party IR data into analyst workflows that are trustworthy and fully verifiable. We’re proud to be the infrastructure they’re building on.”
— Oscar Küntzel, co-founder and CEO, Quartr
Where this goes
Kepler’s corpus already runs to 26 million SEC filings, 50 million additional public documents, and over 1 million private documents, across 14,000 companies in 27 global markets. The 2026 roadmap extends that across more sources, more markets, and adjacent regulated domains.
The architecture is built for finance, but it is not specific to finance. The provenance guarantees we hold ourselves to for an earnings transcript apply just as cleanly to a clinical trial transcript, a court ruling, a regulatory filing, or a procurement record. Finance is the proving ground. The architecture is general.
If your team is running point on earnings season, request a demo.